Schweden. Das Land in dem alle nett sind und das Leben voller Gleichberechtigung, Freiheit und Transparenz höchste demokratische Weihen erreicht hat, nicht? Der Sozialstaat par excellence! Nein, leider nicht. Denn auch dort versuchen Menschen den fragwürdigen Einsatz von maschinellem Lernen (neuerdings unter dem Label KI bekannt) zu nutzen, um Vorhersagen zu treffen, die, gelinde gesagt, auf mangelndes Verständnis oder strategische Ignoranz schließen lassen. Vor allem wenn es um den Zusammenhang von Wahrscheinlichkeitsmodellen und Realität geht. Ein Missverhältnis, das im (Hochfrequenz-)Handel mit Aktien mehr oder weniger zufällig extreme Verluste und Gewinne beschert, teilweise mit enormen wirtschaftlichen und in der Folge gesellschaftlichen Auswirkungen. Denn wenn Millionäre und Milliardäre weniger Gewinn als im Jahr zuvor erleiden, lassen sie den Frust über ihre eigene Massenmedien an vulnerablen Gruppen aus und finden allzu oft Stammtischgeschwister im Geiste, die sich auch sehr gern als zu kurz gekommen erleben. Da sind die extremen Ränder der Gesellschaft oft in Querfront. Leider ist das Problem automatisierter Statistik (maschinelles Lernen) aber zunehmend existentiell für den Rest der Bevölkerung (die breite Mitte), wenn es darum geht, in Aktenbergen der Verwaltungen möglichen Betrügereien von Antragstellern auf die Schliche zu kommen, z.B. beim Elterngeld. Hellhörig sollte man werden, wenn die entscheidenden Kriterien für Betrugsverhalten ein bestimmtes Geschlecht oder eine unschwedische Herkunft sind. Fairness und automatisierte Inferenzstatistik à la KI? Wie soll das gehen? Nun, die Schweden zeigen vor allem, wie es nicht geht – in jeder Hinsicht. Hantieren unerfahrene Kinder oder unwillige Ignoranten mit hoheitlichen Aufgaben?
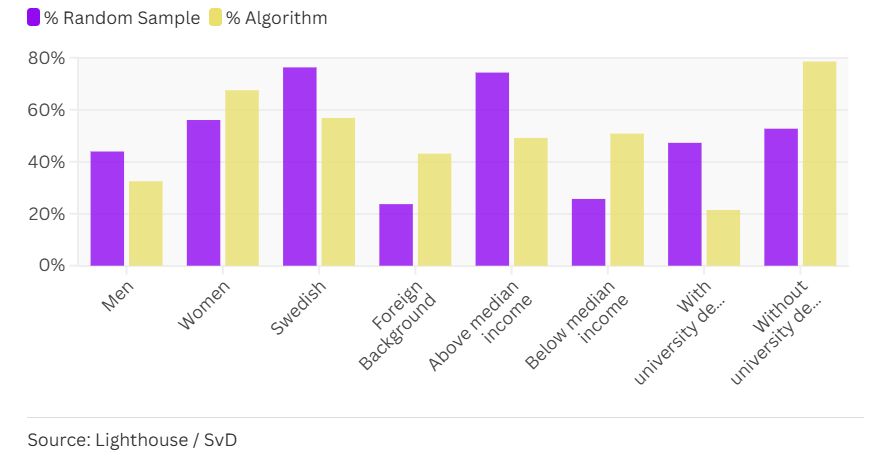
Der Bericht einer unabhängigen Aufsichtsbehörde der Sozialversicherungsanstalt, des ISF, aus dem Jahr 2018 kam auf der Grundlage eines Datensatzes, den die Aufsichtsbehörde erhalten hatte, zu dem Schluss, dass der Algorithmus der Agentur zur Vorhersage von Betrug beim Elterngeld die Antragsteller nicht gleich behandelt. Die Sozialversicherungsanstalt wies diese Einschätzung ihrer Aufsichtsbehörde zurück und stellte die Gültigkeit der durchgeführten Analyse in Frage. Mithilfe eines realen Datensatzes mit mehr als 6.000 Personen, die 2017 vom Algorithmus zur Untersuchung markiert wurden, führten acht Experten und Journalisten (Lighthouse und Svenska Dagbladet) statistische Fairness-Tests durch, um zu bewerten, welche Gruppen überzufällig oft betroffen waren. Die Analyse ergab, dass Frauen, Migranten, Geringverdiener und Menschen ohne Hochschulbildung von dem Modell diskriminiert wurden. Zudem wurde festgestellt, dass Personen aus diesen Gruppen, die sich nichts zuschulden kommen ließen, vom System mit größerer Wahrscheinlichkeit fälschlicherweise als verdächtig eingestuft wurden (Details hier).
Der Fall zeigt einmal mehr, dass gefährdete Gruppen, die seit jeher diskriminiert werden, auch die Gruppen sind, die am ehesten zu Unrecht für Ermittlungen ausgewählt werden, da Software auf Basis maschinellen Lernens (aktuell die Methode der Wahl bei derartigen KI-Lösungen), Mitglieder dieser Gruppen überzufällig oft markiert. Interessant ist die Begründung der Behörde, dass Betrug beim Elterngeld besonders häufig vorkomme (was nicht stimmte), und das man Maßnahmen ergreifen musste. Eine Analyse ergab jedoch, dass häufig Fehler beim Ausfüllen der Anträge als Betrug gewertet wurden und so die Anzahl der „Betrüger“ künstlich aufgebauscht wurde. Möglicherweise haben die Behörden das Problem, das maschinelles Lernen lösen sollte, selbst geschaffen, mindestens aber keine Interesse daran, dass das Ausfüllen eine Hürde darstellt, die nicht jeder leicht überspringt. Spekulationen über die Gründe für komplizierte Antragsformulare überlassen wir gern den Lesenden. Festhalten kann man, dass diese Form der Anträge, anders als bei anderen Bevölkerungsgruppen nicht von Steuerberatern oder Anwälten ausgefüllt werden.
David Nolan vom Algorithmic Accountability Lab von Amnesty kritisierte gegenüber den schwedischen Journalisten, die den Sachverhalten recherchiert und zusammen mit Experten geprüft hatten, den Mangel an Rechtsmitteln für Bürger, die von dem System erfasst werden. „Die Undurchsichtigkeit des Systems bedeutet, dass die meisten Menschen nicht wissen, dass Algorithmen zur Betrugsbekämpfung verwendet wurden, um sie für weitere Untersuchungen zu markieren“, erklärte Nolan. „Wie sollen Einzelpersonen eine über sie getroffene Entscheidung wirksam anfechten – was ihr Recht ist -, wenn sie wahrscheinlich nicht wissen, dass sie Gegenstand eines automatisierten Prozesses sind?“
Maschinelles Lernen und KI sind tolle Werkzeuge in den richtigen, verantwortungsvollen Händen und können Leben retten, wie aktuell in der Proteinforschung erkennbar (wir erinnern uns an die rasend schnelle Entwicklung der Corona-Vakzine, die ohne KI wahrscheinlich Jahre gedauert hätte). Aber es wäre ganz gut, wenn jemand den Menschen, die mit KI hantieren das Kuratieren der Lernmenge beibringen würde. Oder zumindest zur Vorsicht und Prüfung mahnen. Ob und wie die Risikoklassen von KI bei Behörden geprüft und gewährleistet werden (AI Act/KI-VO) wird hoffentlich Teil der nächsten Wahlkämpfe werden. Wenn nicht, stehen uns böse Zeiten bevor, auch und gerade in vermeintlich demokratischen und transparenten Staatsgebilden. Eigentlich hätte jemand das Paper von 2022 lesen und verstehen müssen.
Hoffen wir, dass wenigstens ein deutscher KI-Experte, den die Regierung befragen wird, die breite Literatur zu Risiken zur Kenntnis genommen UND verstanden hat. Und hoffen wir, dass Firmen kluge Berater zum Thema Fairness finden. Die Haftungsfrage hat das Potenzial, ganze Konzerne in Probleme zu bringen – auch saußerhalb der Prüfung der Anbieter und Betreiber mittels KI-VO (AI Act). Wünschen wir den Behörden ein paar neue Entgeltgruppen, damit auch jemand mit Kontextwissen UND profunder Ausbildung in die Ministerien findet.
Quelle Risiken: https://dl.acm.org/doi/fullHtml/10.1145/3531146.3533088
Quelle Fairness: https://dl.acm.org/doi/10.1016/j.ijhcs.2022.102954 https://journals.sagepub.com/doi/10.1177/10591478241234998?icid=int.sj-abstract.citing-articles.2
Quelle Material/Untersuchung: https://www.lighthousereports.com/methodology/sweden-ai-methodology/